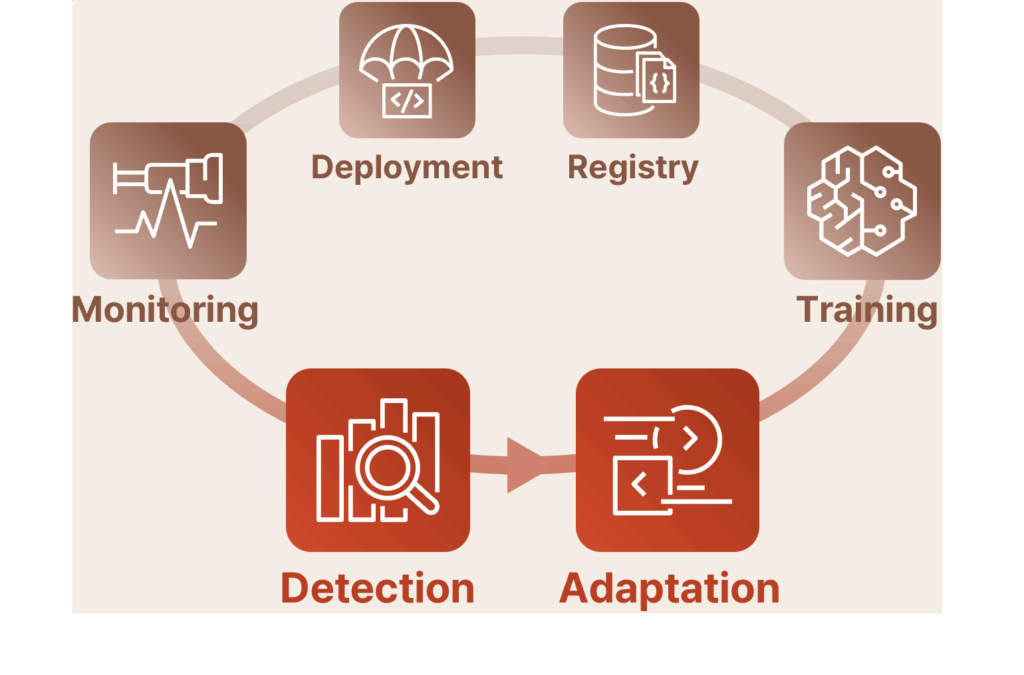
Identification of concept drift detection criteria
Identification of concept drift
adaptation procedures
Customization of
feature and data store
management strategies
MOTIVATION
Unspoken Issue of AI
Performance drop after deployment is not an exception Retraining takes time, money, and often guesswork Retraining strategies rarely match real-world needs Your models are running, but are they still learning?
MOTIVATION
Unspoken Issue of AI
Post-deployment performance drop is routine
Retraining takes time, money, and often guesswork
Retraining strategies rarely match real-world needs
Your models are running, but are they still learning?
SOLUTION
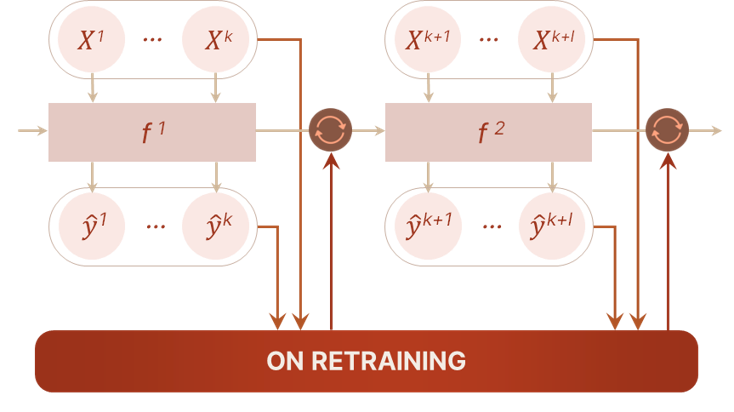
Auto-Retraining
Tailors retraining strategies to your environment Pinpoints the right time and right way to retrain Modular architecture for seamless integration Keeps your model sharp with autonomous improvement
Tailors retraining strategies to your environment
Pinpoints the right time and right way to retrain
Modular architecture for seamless integration
Keeps your model sharp with auto-tuning
DETECTION
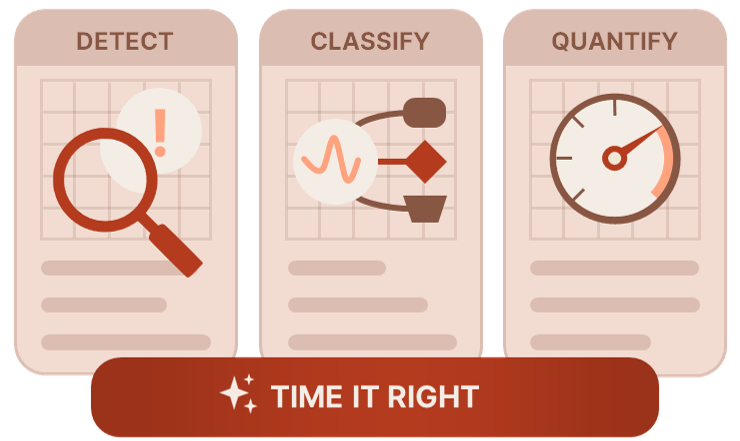
When To Update
Precisely detect the right moment to update Accurately classify emerging data trends Measure and interpret concept drifts with clarity Enable intelligent and automated model updates
Precisely detect the right moment to update
Accurately classify emerging data trends
Measure and interpret concept drifts with clarity
Enable intelligent and automated model updates
ADAPTATION
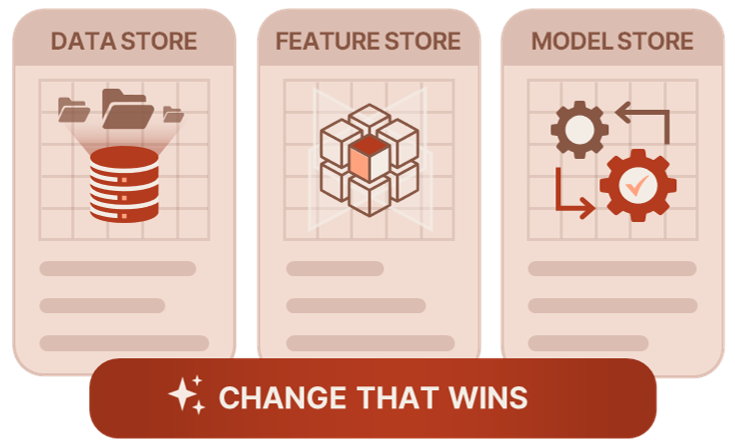
How To Update
Empower cumulative data through data store updates Reinvent predictor structures with feature store updates Elevate model performance with model store updates Adaptive update strategies crafted for data evolution
Empower cumulative data through data store updates
Evolve predictors through feature store updates
Elevate model performance with model store updates
Adaptive update strategies crafted for data evolution
DIAGNOSIS
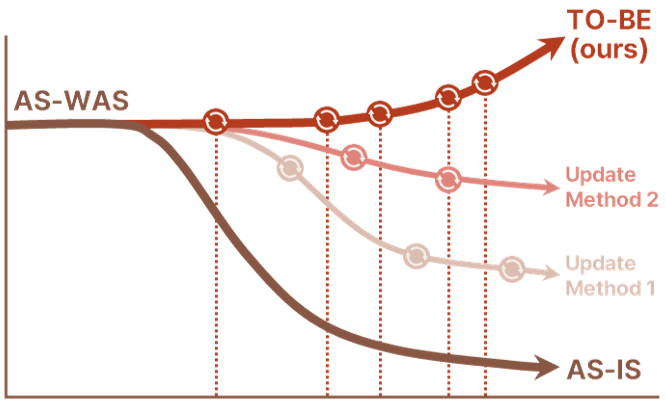
See What Works
Run wide-scale tests to measure retraining impact Simulate retraining scenarios for peak performance Validate both feature replacement and model swap strategies Build a strategy for storing, learning, and referencing data
Run wide-scale tests to measure retraining impact
Simulate retraining scenarios for peak performance
Validate feature updates and model swap strategies
Plan how to store, learn from, and reference data
TREATMENT
Make It Work
Plug into legacy systems via simple scheduling hooks Integrate directly into your MLOps pipeline as a CI/CD module Visualize it all through your existing dashboards Sync with your feature and data stores for full-cycle control
Plug into legacy systems via simple scheduling hooks
Integrate with your MLOps pipeline as a CI/CD module
Visualize it all through your existing dashboards
Sync with your feature and data stores for full control
News
Joining the Sovereign AI Foundation Model Project
Industrial operations optimization powered by independently developed foundation models
Jun 10, 2026
POSCO BPED Operational System Development (ONGOING)
Widely running retraining impact tests to optimize model performance
Since 2025
Nine ML/AIOps-related Patents Registered in 2025
Relentlessly advancing IP strategy to drive future growth
Dec 31, 2025
News
Joining the Sovereign AI Foundation Model Project
Industrial operations optimization by independently developed foundation models
Jun 10, 2026
POSCO BPED Operational System Development (ONGOING)
Widely running retraining impact tests to optimize model performance
Since 2025
Nine ML/AIOps-related Patents Registered in 2025
Relentlessly advancing IP strategy to drive future growth
Dec 31, 2025
LG U+ Voice Phishing Detection Model (OPTIMIZED)
Running wide-scale tests to measure retraining impacts